Prometheus와 Grafana를 활용해 데이터를 수집하고 대시보드를 구성하던 중, 기존에 설정된 패널에서 "Found Duplicate Series for the Match Group" 오류가 발생하며 정상적으로 데이터를 표시하지 못하는 문제가 발생했습니다. 이 글에서는 해당 오류가 발생한 원인과 해결 방법을 정리합니다.
2. 오류 발생 원인
2.1 문제가 발생한 PromQL 쿼리 예시
오류가 발생한 PromQL 쿼리는 SNMP Exporter를 통해 수집한 ifHcInoctets 메트릭(네트워크 인터페이스의 바이트 단위 수신량)을 활용한 아래와 같은 형태였습니다.
이 쿼리는 특정 instance 및 type에 해당하는 네트워크 트래픽 데이터를 가져오는 과정에서 중복된 시계열(series)이 존재하여 오류가 발생한 것입니다.
2.2 type 라벨 중복 문제
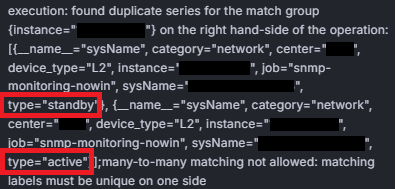
오류의 원인은 type 라벨에 두 개의 서로 다른 값(“active”와 “standby”) 이 존재했기 때문입니다. 이는 연동 작업 중 IP 설정 오류로 인해 원래 type='standby'로 설정되어야 할 대상이 type='active'로 잘못 설정되었고, 이후 이를 수정하여 Prometheus를 재시작하면서 동일한 instance에 대해 두 개의 type 값을 가지는 시계열이 생성되었기 때문입니다.
Prometheus에서는 동일한 instance와 같은 라벨 조합을 가진 메트릭이 중복될 경우, irate()와 같은 함수에서 오류가 발생할 수 있습니다. 아래는 실제 패널상에서 보여지는 에러이미지입니다.
3. 해결 방법
중복된 시계열을 해결하는 방법은 여러 가지가 있습니다.
3.1 불필요한 메트릭 삭제 (필자가 선택한 방법)
*delete_series API 사용 방법
해당 메트릭이 실수로 수집된 것이므로 사용하지 않도록 제거하는 방법을 선택했습니다. Prometheus의 delete_series API를 사용하면 특정 메트릭을 삭제할 수 있습니다.
curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={instance="10.10.10.10",type="active"}'
이 명령어를 실행하면 특정 instance 값과 일치하는 시계열 데이터가 삭제됩니다.
* Admin API 활성화 필요
하지만 기본적으로 Prometheus는 admin-api가 비활성화되어 있어, 위 명령어를 실행하면 다음과 같은 오류가 발생할 수 있습니다.
이 경우 Prometheus 설정 파일 또는 실행 인자에 다음 옵션을 추가해야 합니다.
--web.enable-admin-api
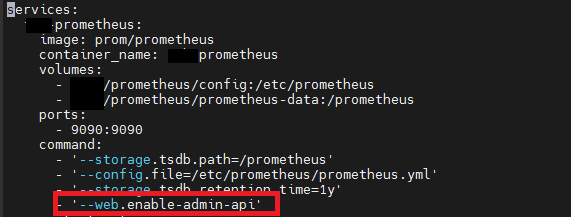
필자는 Prometheus를 Docker Compose로 운영 중이므로, docker-compose.yml 파일에서 아래 이미지와 같이 Prometheus 컨테이너에 해당 옵션을 추가한 후 재시작했습니다.
설정을 추가한 후 Prometheus를 재시작하고 다시 delete_series API를 실행하면, 중복된 시계열이 삭제되며 정상적으로 Grafana 패널이 표시되는 것을 확인할 수 있습니다.
4. 결론
이번 오류는 Prometheus에서 동일한 instance에 대해 두 개의 type 값(active/standby)이 존재하여 중복된 시계열이 생성되면서 발생했습니다. 해결 방법으로는 불필요한 시계열 삭제, PromQL 쿼리 수정 등을 선택할 수 있으며, 필자는 delete_series API를 활용해 메트릭을 삭제하는 방식으로 해결했습니다.
Prometheus와 Grafana를 운영하면서 중복된 시계열 문제를 방지하려면, 라벨 관리에 신경 쓰고 불필요한 중복 데이터를 최소화하는 것이 중요합니다. 이후 동일한 문제가 발생하지 않도록 수집 설정을 주의 깊게 관리하는 것이 필요합니다.